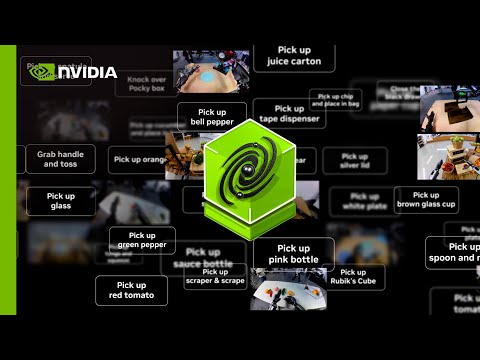
NVIDIA Isaac GR00T-Dreams blueprint generates vast amounts of synthetic trajectory data using NVIDIA Cosmos world foundation models, prompted by a single image and language instructions. This enables robots to learn new tasks in unfamiliar environments without needing specific teleoperation data.
As a first step, we release DreamGen: Unlocking Generalization in Robot Learning through Video World Models Website | Paper
We provide the full pipeline for DreamGen, as Cosmos-Predict2 as the video world model in the repository. This repository is divided into:
- Finetuning video world models
- Generating synthetic videos
- Extracting IDM actions
- Fine-tuning on GR00T N1
- Replicating the DreamGenBench numbers
Install the environment for cosmos-predict2 following cosmos-predict2-setup.
See cosmos-predict2/documentations/training_gr00t.md for details.
See cosmos-predict2/documentations/training_gr00t.md#inference-for-dreamgen-benchmark for details.
This step convert the directory structure from step 2 to the format required by step 3.2.
This scripts convert the directory structure from step 2 for step 3
in step 2, the directory structure is like this:
results/dream_gen_benchmark/
└── cosmos_predict2_14b_gr1_object/
├── 0_Use_the_right_hand_to_pick_up_the_spatula_and_perform_a_serving_motion_from_the_bowl_onto_the_metal_plate.mp4
├── 1_Use_the_right_hand_to_close_lunch_box.mp4
└── ...
For step 3, the directory structure is like this:
results/dream_gen_benchmark/
└── cosmos_predict2_14b_gr1_object_step3/
├── Use_the_right_hand_to_pick_up_the_spatula_and_perform_a_serving_motion_from_the_bowl_onto_the_metal_plate/0.mp4
├── Use_the_right_hand_to_close_lunch_box/0.mp4
└── ...Save the generated video from cosmos-predict2 in ${COSMOS_PREDICT2_OUTPUT_DIR} in step2.
python IDM_dump/convert_directory.py \
--input_dir "${COSMOS_PREDICT2_OUTPUT_DIR}" \
--output_dir "results/dream_gen_benchmark/cosmos_predict2_14b_gr1_object_step3"Scripts are below IDM_dump/scripts/preprocess folder. Replace the source_dir with your own dataset path that contains generated videos in the command. Each script is designed for a specific embodiment. We currently support the following embodiments:
franka: Franka Emika Panda Robot Armgr1: Fourier GR1 Humanoid Robotso100: SO-100 Robot Armrobocasa: RoboCasa (Simulation)
NOTE: This is only needed if the target embodiment is different from the 4 embodiments that we provide (franka, gr1, so100, and robocasa).
Given a few ground-truth trajectories of a specific embodiment, we can train an IDM model.
The following example command will train an IDM model on robot_sim.PickNPlace demo dataset.
PYTHONPATH=. torchrun scripts/idm_training.py --dataset-path demo_data/robot_sim.PickNPlace/ --embodiment_tag gr1Here's another example command that will train an IDM model on the robocasa_panda_omron embodiment (RoboCasa simulation).
PYTHONPATH=. torchrun scripts/idm_training.py --dataset-path <path_to_dataset> --data-config single_panda_gripper --embodiment_tag "robocasa_panda_omron"For other embodiments, you need to add two things: 1)modality.json and stats.json below IDM_dump/global_metadata/{embodiment_name}, 2) data config information for the new embodiment below gr00t/experiment/data_config_idm.py.
Scripts are below IDM_dump/scripts/finetune folder. Each script is designed for a specific embodiment. We currently support the following embodiments:
franka: Franka Emika Panda Robot Armgr1: Fourier GR1 Humanoid Robotso100: SO-100 Robot Armrobocasa: RoboCasa (Simulation)
The recommended finetuning configurations is to boost your batch size to the max, and train for 20k steps.
Run the command within the DreamGen environment.
We provide the code to evaluate Instruction Following (IF) and Physics Alignment (PA) from the DreamGen paper.
make sure that your directory of video & name of videos is structured as:
/mnt/amlfs-01/home/joelj/human_evals/
└── cosmos_predict2_gr1_env/
├── 0_Use_the_right_hand_to_pick_up_the_spatula_and_perform_a_serving_motion_from_the_bowl_onto_the_metal_plate.mp4
├── 1_Use_the_right_hand_to_close_lunch_box.mp4
├── 2_Use_the_right_hand_to_close_the_black_drawer.mp4
├── 3_Use_the_right_hand_to_close_the_lid_of_the_soup_tureen.mp4
.......# success rate (evaluated by Qwen2.5-VL)
video_dir={YOUR_VIDEO_DIR} # structured as mentioned above
csv_path={PATH_TO_SAVE}
device="cuda:0"
python -m dreamgenbench.eval_sr_qwen_whole \
--video_dir "$video_dir" \
--output_csv "$csv_path" \
--device "$device"
# if you are a zero-shot model, you can specify zeroshot as the flag
python -m dreamgenbench.eval_sr_qwen_whole \
--video_dir "$video_dir" \
--output_csv "$csv_path" \
--device "$device" \
--zeroshot true
# success rate (evaluated by GPT-4o)
video_dir={YOUR_VIDEO_DIR} # structured as mentioned above
csv_path={PATH_TO_SAVE}
api_key={YOUR_OPENAI_API_KEY}
device="cuda:0"
python -m dreamgenbench.eval_sr_gpt4o_whole \
--video_dir "$video_dir" \
--output_csv "$csv_path" \
--api_key "$api_key"
# if you are a zero-shot model, you can specify zeroshot as the flag
python -m dreamgenbench.eval_sr_gpt4o_whole \
--video_dir "$video_dir" \
--output_csv "$csv_path" \
--zeroshot true \
--api_key "$api_key"
# physical alignment (using QWEN-VL, get PA score I)
python -m dreamgenbench.eval_qwen_pa
--video_dir "$video_dir" \
--output_csv "$csv_path" \
--device "$device"
please refer to the README in videophy folder to evaluate the PA score II, then average the score of PA score I & II
Our benchmark hopes to be friendly enough to the research community, thus only choosing ~50 videos for each dataset and using a relatively small open source VLM for major evaluation. Thus, our evaluation protocol might not be generalized well to some OOD scenarios like multi-view videos, judging physics in a detailed manner, etc.
@article{jang2025dreamgen,
title={DreamGen: Unlocking Generalization in Robot Learning through Video World Models},
author={Jang, Joel and Ye, Seonghyeon and Lin, Zongyu and Xiang, Jiannan and Bjorck, Johan and Fang, Yu and Hu, Fengyuan and Huang, Spencer and Kundalia, Kaushil and Lin, Yen-Chen and others},
journal={arXiv preprint arXiv:2505.12705v2},
year={2025}
}